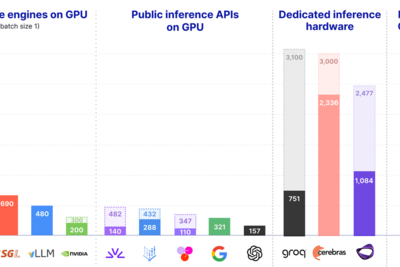
Real-time LLM Inference on Standard GPUs: 3k tokens/s per request
Article URL: https://blog.kog.ai/real-time-llm-inference-on-standard-gpus-3-000-tokens-s-per-request/
Comments URL: https://news.ycombinator.com/item?id=48321076
Points: 18
# Comments: 11
Read Full Article →